We Are Still Improving the Software That Runs This Site

AS noted a few hours ago in the sister site, work continues on the software which runs this site too and changes are made accessible in Git, publicly available over Gemini Protocol.
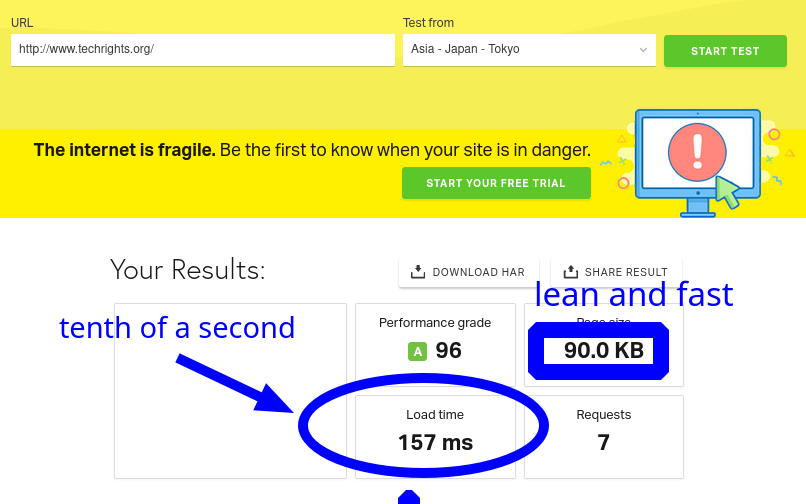
Our site is hosted in the UK, so obviously requests from the UK will be served quickly (on our own network, which uses fibre, it takes less than a tenth of a second to load pages; apparently it's also fast from other places*).
We have many plans for this site, including articles that are scheduled for next year, and making our own systems lets us tailor everything to improve productivity. Rather than having to adapt to someone else's system (and change habits any time a major new version comes out) we build the systems to suit our needs.
Thankfully, aside from writing we can also code and do sysadmin work. It's a huge advantage.
Implementing site search, which would be locally hosted (nope, no Google!), can expose us to DDoS attacks, in effect swarming the site (server) with CPU-intensive and RAM-hoarding processes at the back end. We've discussed search for a long time here; search isn't so simple to do when one considers the high and ever-increasing proportion of Web activity that's just bots, including so-called 'AI' hoarders. One reason we left Drupal, MediaWiki, and WordPress behind (all three were used in tandem here for well over a decade!) is the constant churn at the back end. It used to always hover around load average of ~5, sometimes even 30+, spread across many CPU cores. It's expensive and it is bad for the planet.
This is what running a static site looks like:
uptime 03:48:04 up 106 days, 20:44, 13 users, load average: 0.00, 0.01, 0.00
Make no mistake! The site is very active, but it is serving static pages that are small and mostly require the network system (LAN-like layer), not the CPU with some RAM allocation (to access a database). █
_____
* This morning's benchmark: