
Slopwatch: Stigma-Baiting by the Serial Sloppers and Latest Garbage From the Slopfarm LinuxSecurity.com (Also Slopping Away at "OpenBSD" With SEO SPAM Made by LLMs)
A few hours ago I saw this 'article':
Upon some analysis the first few paragraphs are mildly edited LLM slop. The remainder looks like nothing but a words salad spewed out by LLMs:
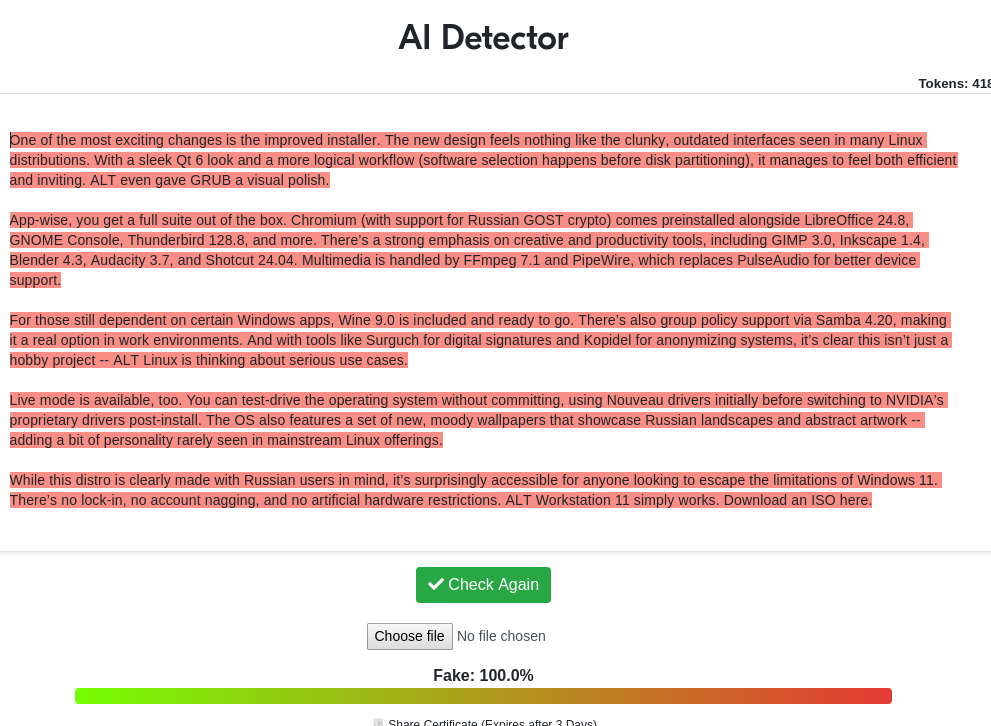
Typical Fagioli. BetaNoise still tolerates this. Slop images, slop text. Anything goes...
But then there's the slopfarm LinuxSecurity.com, which is not only targeting "Linux" with SEO SPAM produced by LLMs. Now there's this:
This is basically slop about what happened in Kali Linux:
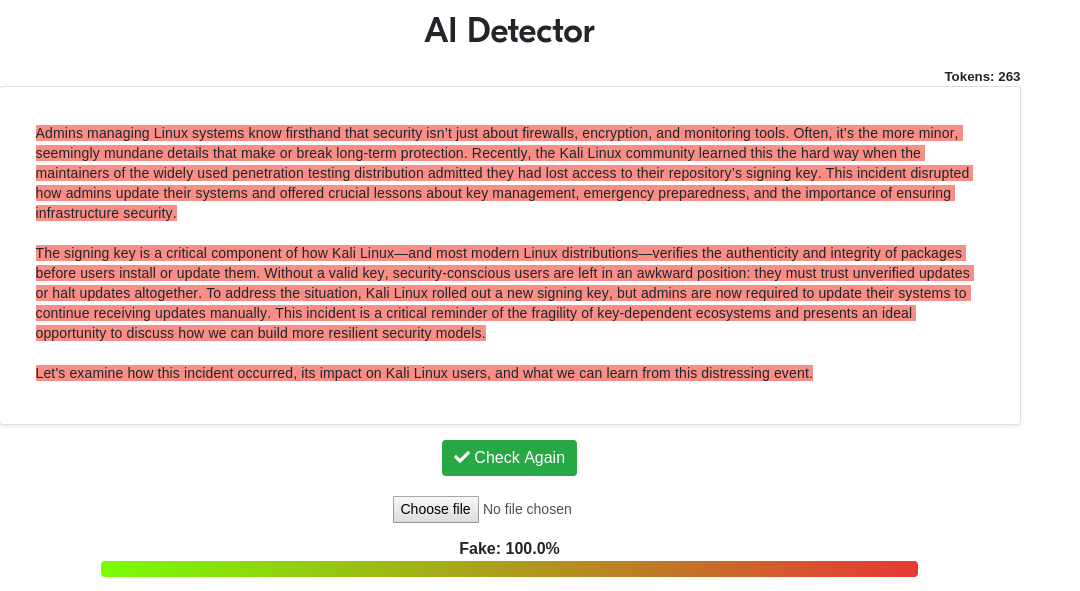
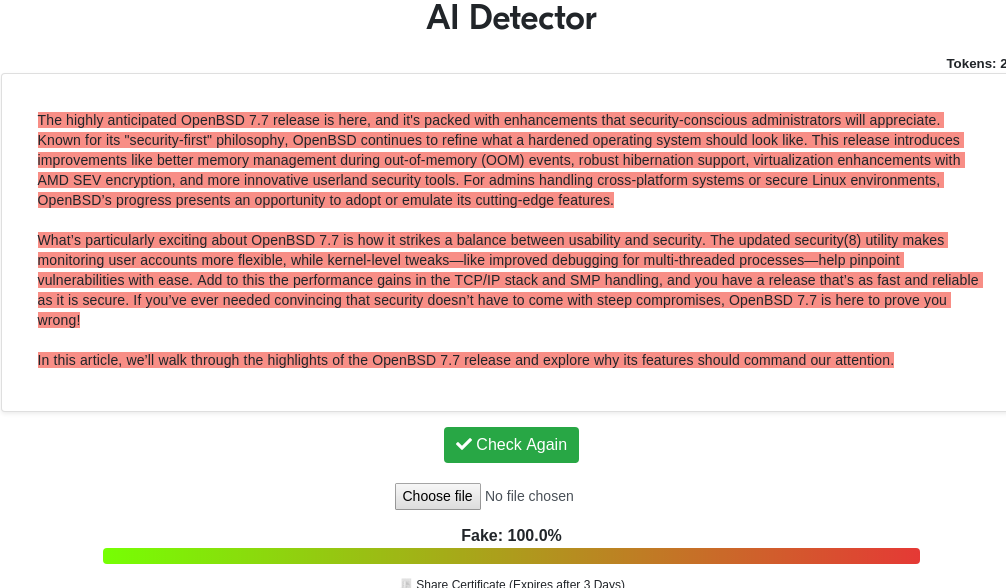
If that's not bad enough, they also targeted the OpenBSD 7.7 release on the same day:

Being a slopfarm (which is what LinuxSecurity.com is), of course these fakers didn't bother writing:
These slopfarms and people who sling around fake images that fuse together other people's work without attribution (a form of plagiarism) not only spread misinformation about Linux and the BSDs. There are slopfarms which target other themes. We just leave them aside because they are less relevant to us.
Microsoft et al are trying to profit from blurring away information. They call it "AI", but it has nothing to do with intelligence. The other day we quoted a message by Akira Urushibata, who complained about Google misinforming him. "Obviously the above text was generated by AI," he said, but calling it AI is also wrong. Jean Louis responded to him yesterday at libreplanet-discuss:
> Other items of the list discussed ticket prices, access to the > grounds. Obviously the above text was generated by AI, for it is > unlikely for a human being to err in this manner, but Google does not > clarify. (Confirmed April 28 Japan time) So, one part of Google > (probably AI) treats the exposition as canceled while another part > understands that it is in progress. There is a failure to notice > an obvious contradiction.
It is their organization. You can complain to them. Take it realistically, you can't do nothing much about organizations that are not under your control.
Don't expect "corporate responsibility" as they are money driven, they have responsibility to making income, not to random people.
> Can AI distinguish between "free" as in "free drinks" and "free" as in > "freedom"?
Run the so-called "AI" or the Large Language Model (LLM) on your own computer and find it out!
See https://www.gnu.org/philosophy/words-to-avoid.html#ArtificialIntelligence
The word AI as such is not wrong, but when used in wrong context for sensationalism or anthropomorphism of computer programs it leads people to wrong conclusions. Point is that it doesn't think.
Your message proves that it doesn't think.
Back to question if Large Language Model (LLM) can understand "free" as in freedom related to free software:
- ask your favorite LLM what is free software. Sample answer by GLM-4-9B-0414-Q8_0.gguf Large Language Model (LLM) says that it can understand it: https://gnu.support/files/tmp/clipboard-2025-05-01-08-35-21.html
If you start talking to the LLM in the context of price, it may probably answer in that way. Let's try:
> I can't afford Microsoft proprietary software, should I instead use free > software?
Answer: https://gnu.support/files/tmp/clipboard-2025-05-01-08-37-51.html
Answer is quite aligned to meanings of free software.
I have other 100 models which I could test, but there is no need to exaggerate. I can tell you that my experience is that it does understand the meaning of free software as majority of models have been trained on information which provides those meanings.
> We should watch out for this.
You can watch, but is waste of time.
If you wish to make things right, take datasets and fine-tune some models. But I think that is also waste of time.
The effort to correct society on the importance of free software, especially when common knowledge lacks sufficient references, would be like trying to teach a new language to a community that still speaks an old one.
Reality is that there is sufficient information on free software and that information is part of each Large Language Model (LLM) so far that I have tried out, it is more than 100+ different Large Language Models (LLM).
> The above makes me think that we should not expect much.
Expecting is passive attitude of an observer. You can be causal and influence society.
First is to understand that you can run the Large Language Model (LLM) locally.
THUDM/GLM-4: GLM-4 series: Open Multilingual Multimodal Chat LMs | 开源多语言多模态对话模型 https://github.com/THUDM/GLM-4
Get your hardware and run it locally.
There is no point in staying behind the computer technology developments. Run it locally, do the research, understand that there there many many different Large Language Model (LLM) and then start benchmarking and testing.
> Even if we observe AI getting the distinction right in a number of > cases we should not expect it to be always correct.
Good conclusion!
I consider all information generated by the Large Language Model (LLM) as a draft of a possibly correct answer.
> For one thing many people are confused and much has been written > based on the mistake. it is unreasonable to expect that none of the > erroneous material has been fed to the large language model (LLM) > neural networks for training. In addition the above example > indicates that AI is not good at coping with lack of integrity. > Perhaps a contradiction which is obvious to a human being is not > so for AI.
What is erroneous material or not, is not subject for the Large Language Model (LLM). That is subject of human discussions and opinions.
There is no right or wrong for the Large Language Model (LLM).
Datasets used in training are by the rule biased by people who created There is no right or wrong for the llmthe information.
There is no right or wrong for the Large Language Model (LLM).
It is like watching TV stations over the world. You cannot get the single objective truth, but you get variety of human information where you need to keep the principle of deciding what is right or wrong for yourself.
Anybody who thinks “let me teach Large Language Model [LLM] what is right or wrong” is automatically creating a new biased and censored version that won’t represent information to the user so they can decide about it, as what was considered wrong by the author may not be wrong for the user.
Your attempt of wronging any Large Language Model (LLM) is futile. It is text generation tool. To blame anyone condition is to know who was responsible for "training" of the Large Language Model (LLM). And why do that in first place? Anybody can make their own Large Language Model (LLM), similarly like people are creating websites individually.
> Related article: Researchers have found methods to investigate what is > going on inside the neural networks that power AI. They have > discovered that the process differs greatly from human reasoning.
There are sciences of mind though so far there is no consensus how human mind works exactly. I don't think we have a stable information about human reasoning that could be compared to computer base neural networks.
But -- when I hear that researches have found methods to investigate what is going on inside the neural networks, it only means that those were beginners, and there were previous researchers who created neuaral networks knowing exactly what is going on.
So article is in the sense contradictory and sensationalist.
> We Now Know How AI 'Thinks'--and It's Barely Thinking at All > https://www.yahoo.com/finance/news/now-know-ai-thinks-barely-010000603.html
Is not worth reading even. It is made for Yahoo readers, part of entertainment.
It is well established that Large Language Model (LLM) doesn't think. There is no "barely thinking", there is ZERO thinking. It is data and computer program giving you output of that data, giving the impression of mimicking, due to usage of natural language.
I think it is greatest tool so far in 21st century as it empowers human to be 10 times or 100 times faster in various tasks.
Of course, it doesn't think.
> Though I don't follow developments in this field closely, what is > written in this article confirms my suspicions.
Good cognition!
> Another way to see this is that the AI developers now have the > equivalent of a debugger which allows them to probe the internal > process. This is likely to affect development.
Of course! All tokens can be seen, analysed, layers of the Large Language Model (LLM) can be visually inspected, analyzed to every detail when necessary.
Jean Louis
J Leslie Turriff also said: "Far too many people believe the statements that we see about AI that imply that the software can think, when in reality it just strings words together in plausible sequences." "The very term "Artificial Intelligence" is a misnomer; the software is incapable of thinking, only responding to the text of its prompts, and sometimes the response is completely wrong."
"The issue is more fundamental than whether it can distinguish between "libre" and "grtis;" it doesn't think, so doesn't distinguish."
So the starting point is, quit calling it "Artificial Intelligence". You help the companies and charlatans like Scam Altman who lie about the capabilities each time you relay those terms, which are typically misapplied by intention. █