
Mozilla is GAFAM, HTTPS is Monopolies
SHATTERING popular and/or widespread illusions (read: falsehoods) is very important. That Mozilla is a bunch of rubbish became common knowledge in recent years, but what about the practices that Mozilla keeps promoting? Little of what Mozilla does is commendable these days.
Here is what I'm presented with today when attempting to access "Pine64’s Linux E-ink Tablet Is Coming Back":
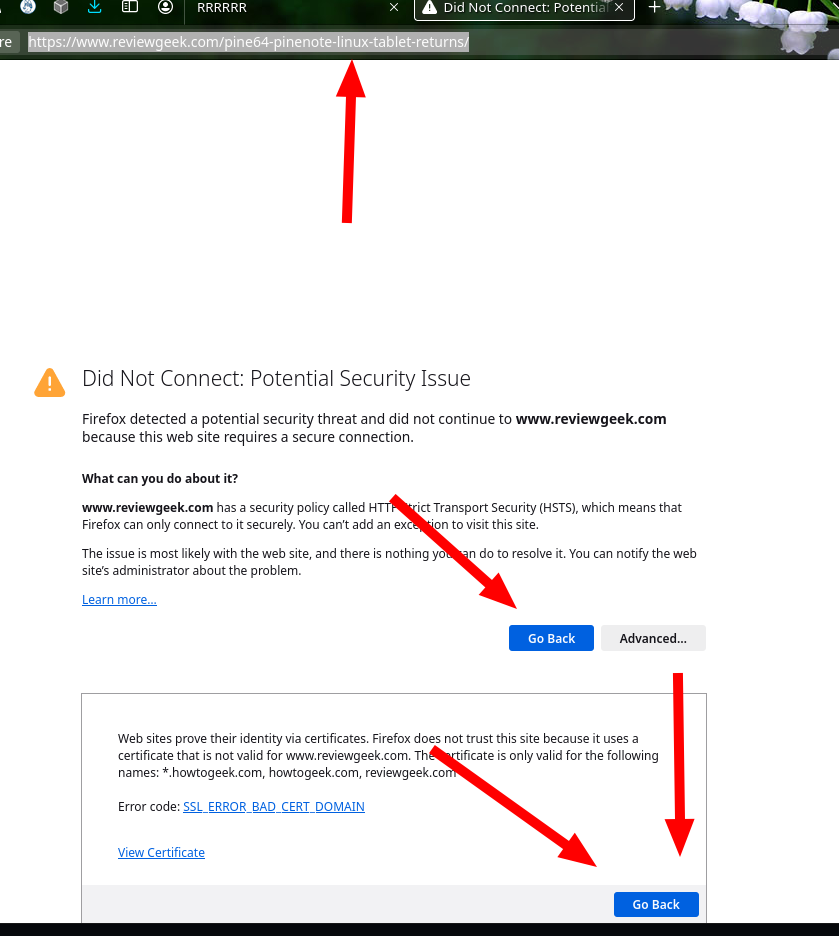
Firefox blocks it. No workaround, perhaps nothing short of tinkering with hidden options somewhere (not only complex; Mozilla added many barriers). Why does Mozilla do this? Who stands to benefit?
One week ago we wrote, "Mozilla's Concept of Web Security: Firefox Cannot Access Wikileaks Because of Clocks or Mindless Bytes" (at a critical time).
Firefox obstructs some very important sites. This isn't about privacy or security, it's all about centralisation. Mozilla is trying to empower GAFAM; it even outsourced itself to it (e.g. Microsoft's GitHub, which is proprietary).
It's a real pain in Firefox. But it works OK in Falkon (just press OK):
Yesterday we spotted a good new post that's a rant about what HTTPS does to "small" sites (or user clients) such as LXer:
HTTPS as an accessibility issue
[...]
Two things have happened recently to shake this perception.
The first was the launch of my silly Ruben’s Retro Corner, which has taken on more of a life than I expected. Several of you have told me you use the site to test retrocomputers, which makes me incredibly happy. More surprising though were the number of people saying they use it as a way to test other machines in a range of different scenarios and use cases. It’s a relatively memorable address, and they know it’s one of the few remaining sites they know will be delivered over plain HTTP.
In the words of moral philosopher Curtis Stigers, it made me wonder why. Granted, I’ve written enough scripts to know that including the requisite libraries to handle HTTPS traffic is an extra step, but I didn’t think it was especially onerous.
It wasn’t until I wrote my post about the promise of HTML and CSS last month that I drew the obvious connection. Not every endpoint supports HTTPS. And we’re shutting them out.
[...]
But this is a pragmatic issue. Many endpoints are old and lack support for modern ciphers, or never had the feature to begin with. Implementing HTTPS everywhere introduces a limitation on the machines, operating systems, and therefore people who can view this. Terence Eden’s 2021 post about this topic is worth a read if you don’t think this is an issue.
This gets us back to the value proposition of HTTPS. Are they… really necessary for a blog without a web-facing admin portal, software downloads, or mission-critical features? Have I shut people out for benefits that don’t really make sense in this context? Have a lot of us?
It might be too late to reconsider reverting back to plain old HTTP for this blog, because I assume endpoints would see a former HTTPS site rendering as HTTP as a security risk. Redirects would also be tricky. But it’s making me re-evaluate my use of it elsewhere.
Ruben Schade nailed it, but there are additional issues associates with this HTTPS 'cargo cult'. We covered those other issues many times in the past.
HTTPS isn't evil, but there are caveats; HTTPS with outsourced and centralised CAs is an even bigger issue.
Shame on Mozilla for wanting to shut out anything but HTTPS and for playing along with this nonsense wherein whatever isn't "blessed" by Pentagon-friendly cabals of CAs must be stubbornly obstructed.
Firefox used to boast that it would make the Web more accessible. Today's Mozilla is rowing in the opposite direction. Today's Mozilla also destroys the planet by promoting "hey hi" (AI) nonsense instead of solving real issues. █